Vor kurzen stand ich vor der Herausforderung eine Rekursion in Databricks umzusetzen.
Da ich aus der Microsoft SQL Welt komme, war mein erster Gedanke dies mit einer CTE (Common Table Expression) zu machen. Das funktioniert aber leider unter Databricks, da CTEs in Databricks keine Rekursion unterstützung.
Nach etwas Recherche bin ich auf den Beitrag von Ryan Chynoweth gestoßen.
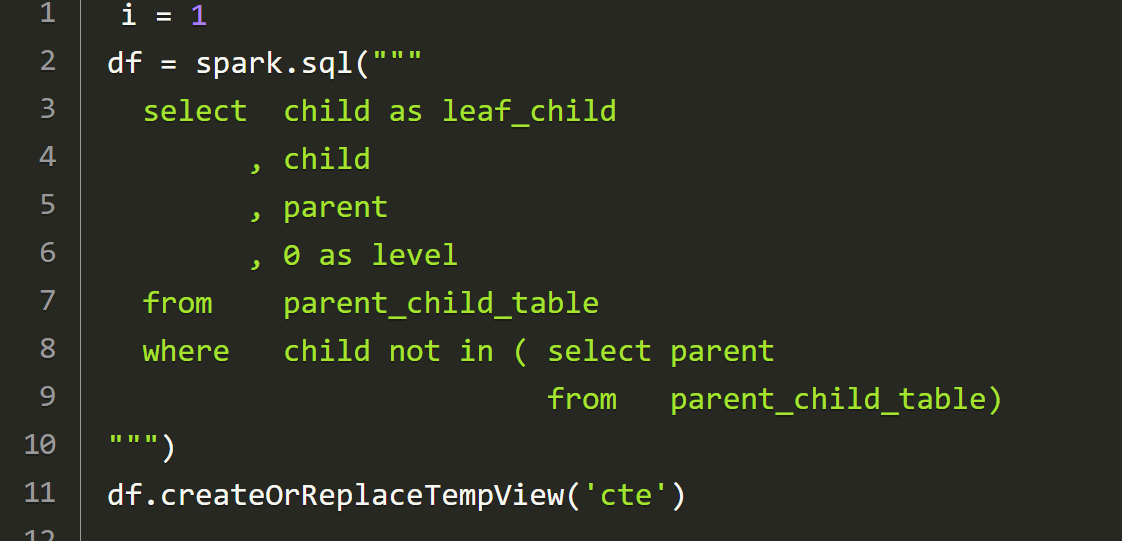
i = 1
df = spark.sql("""
select child as leaf_child
, child
, parent
, 0 as level
from parent_child_table
where child not in ( select parent
from parent_child_table)
""")
df.createOrReplaceTempView('cte')
while True:
rec_df = spark.sql("""
select cte.leaf_child
, source.child
, source.parent
, cte.level + 1 as level
from cte
inner join parent_child_table source on source.child = cte.parent
""")
rec_df.createOrReplaceTempView('cte')
df = df.union(rec_df)
# if there are no results at this recursion level then break
if rec_df.count() == 0:
df.createOrReplaceTempView("final_df")
break
else:
i += 1
spark.sql("""
with cte_max_level as (
select leaf_child
, max(level) max_level
from final_df
group by leaf_child
)
select *
, cte_max_level.max_level - final_df.level as desc_level
from final_df
inner join cte_max_level on cte_max_level .leaf_child = final_df.leaf_child
where 1 = 1
order by level desc
""").display()